
)


)

We want to give back to the wider developer community. Each post in our open source series walks you through a challenge faced by TrueLayer's engineering teams – the code we wrote to solve the issue is released under an OSS license.
In this post, we'll explain how we tackled the challenge of gRPC load balancing in Rust.
Our solution was to release ginepro, a new gRPC channel implementation for tonic. ginepro (github) provides client-side gRPC load balancing by enriching tonic 's channel with periodic service discovery.
The background
TrueLayer has recently started adopting Rust as a backend language. As we deploy more and more services to production we have to constantly improve our applications so that they can handle more load and achieve the required reliability SLAs.
Load balancing gRPC requests has been a challenge: we do not use a service mesh and there was no gRPC client in the Rust ecosystem that satisfied all our requirements.
To bridge the gap we built ginepro – an add-on to tonic's Channel which provides service discovery to perform client-side look-aside gRPC load balancing.
LoadBalancedChannel is a drop-in replacement for tonic's Channel:
The problem
gRPC uses the HTTP/2 protocol to multiplex requests and responses over a single TCP connection.
This allows gRPC to be more efficient: you only pay the cost of establishing a connection once and better utilise the capacity of the underlying transport.
Multiplexing, though, has a few implications when it comes to load balancing.
HTTP/2 load balancing
HTTP/2 connections are persistent: a direct connection between a client (or a load-balancer) and a specific server should remain open as long as possible.
We do not open a new connection to a server every time we want to make a request.
Here we can say that load balancing is done on a per-request basis: for every request the client will choose a new server and issue that request through an existing connection.
But what happens if load balancing is moved out of the client?
Clients will maintain a connection to a load balancer and all requests go through that single connection. Traditional network load balancers, however, are unable to tell application requests apart.
Since network load balancers function at the fourth layer of the OSI stack (known as the transport layer), they can only reason about TCP and UDP connections. Therefore they will only able to forward the traffic from one client to one fixed server (remember that connections are persistent!).

)
To solve this problem HTTP/2 load balancers must be able to inspect the application traffic. This is what application load balancers are for: they can tell requests apart and choose a new server for every incoming one.
Skewed load
Let’s look at a scenario where failing to perform HTTP/2-aware load-balancing can cause servers to be utilised unevenly.
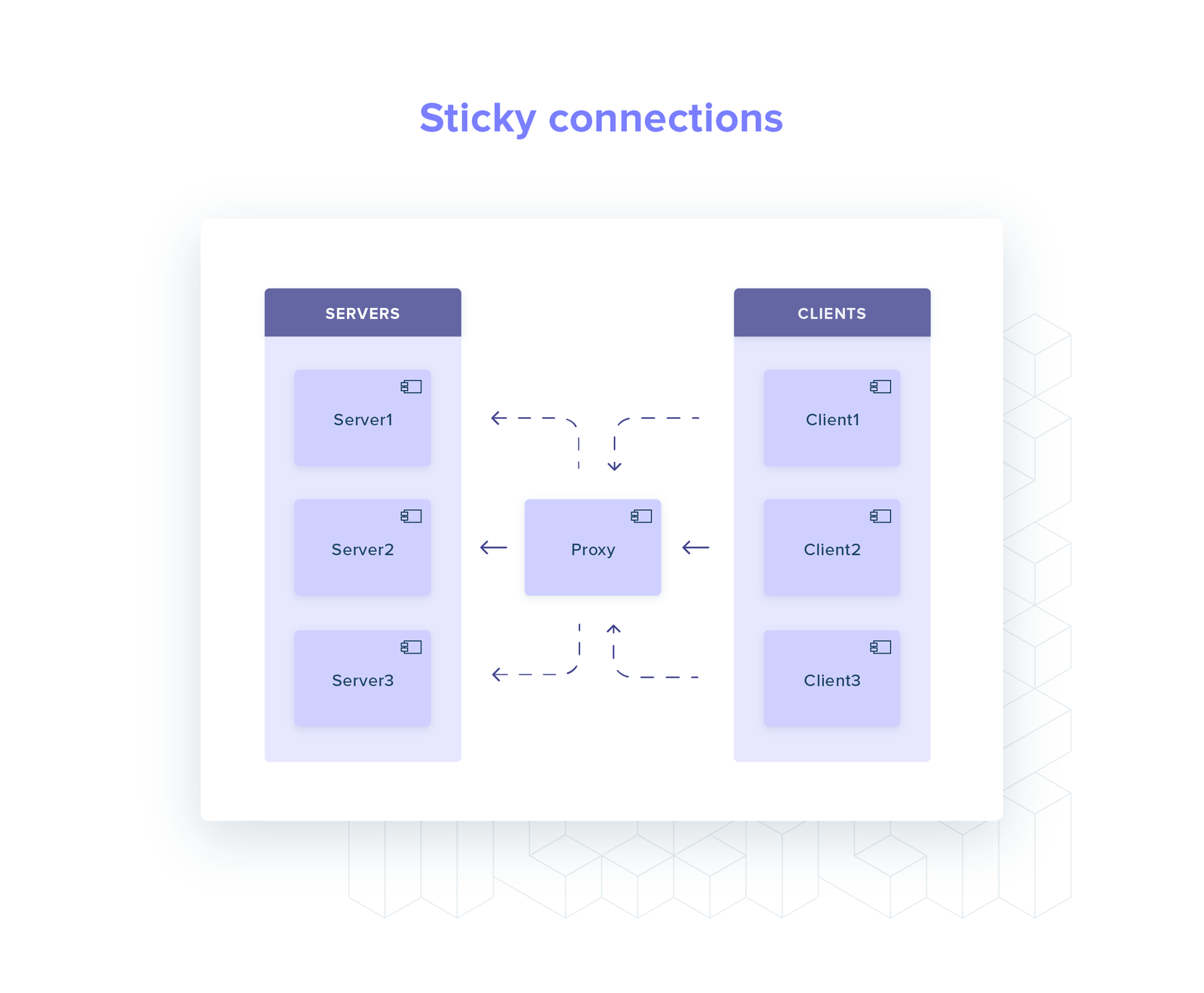
Let’s consider a toy system: one client and two servers, talking gRPC over HTTP/2.

)
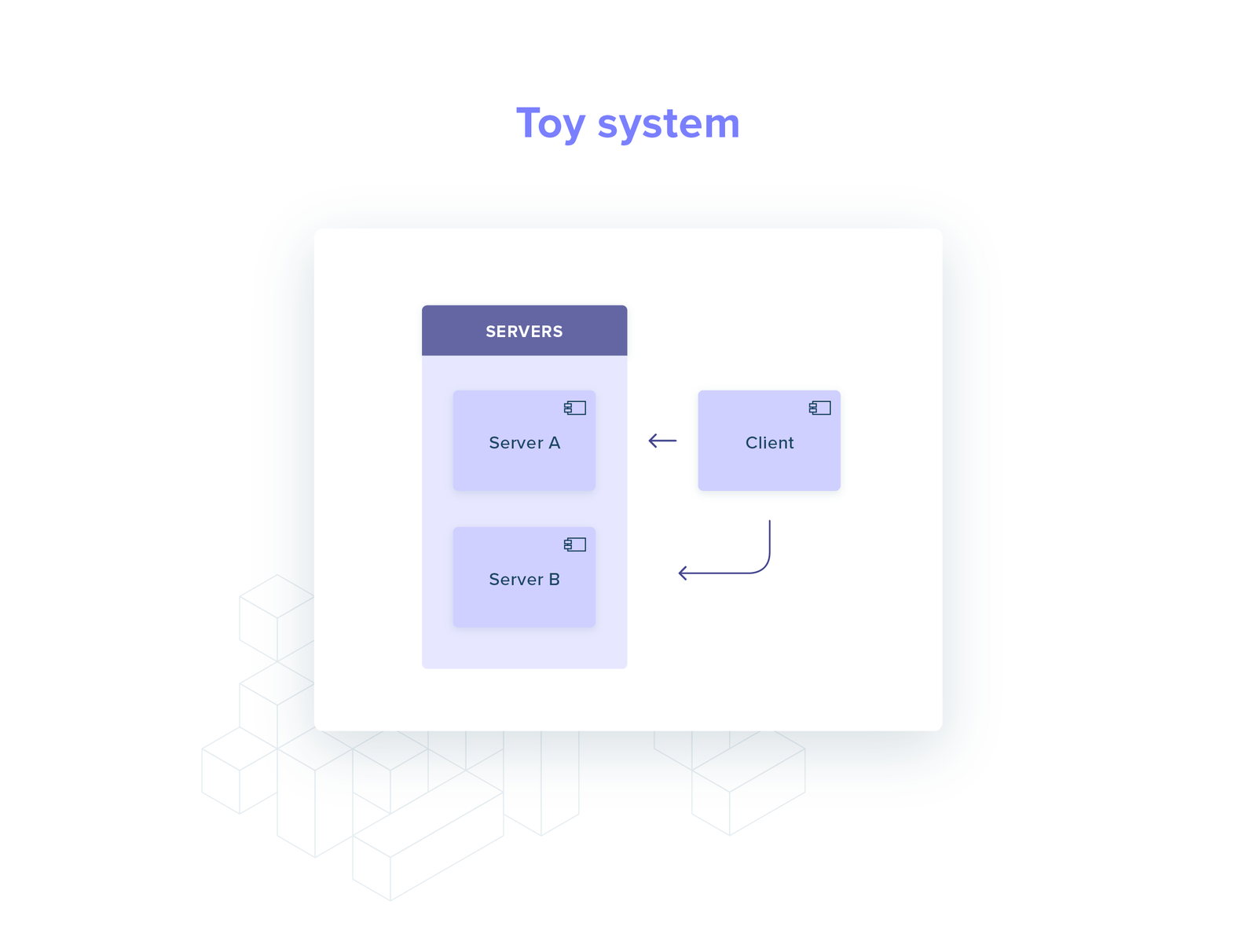
When the client starts up, it performs service discovery (e.g. a DNS query): what IPs can I send my requests to?
The answer is a set with two elements: server A and server B. An HTTP/2 connection is established with each of them.
Every time the client needs to perform a request it now chooses randomly between the two connections (round-robin).
What happens if server A crashes?
In most gRPC implementations, the client will not perform service discovery again.
The client will start routing all its requests to server B, even if server C is spawned to replace server A!
)
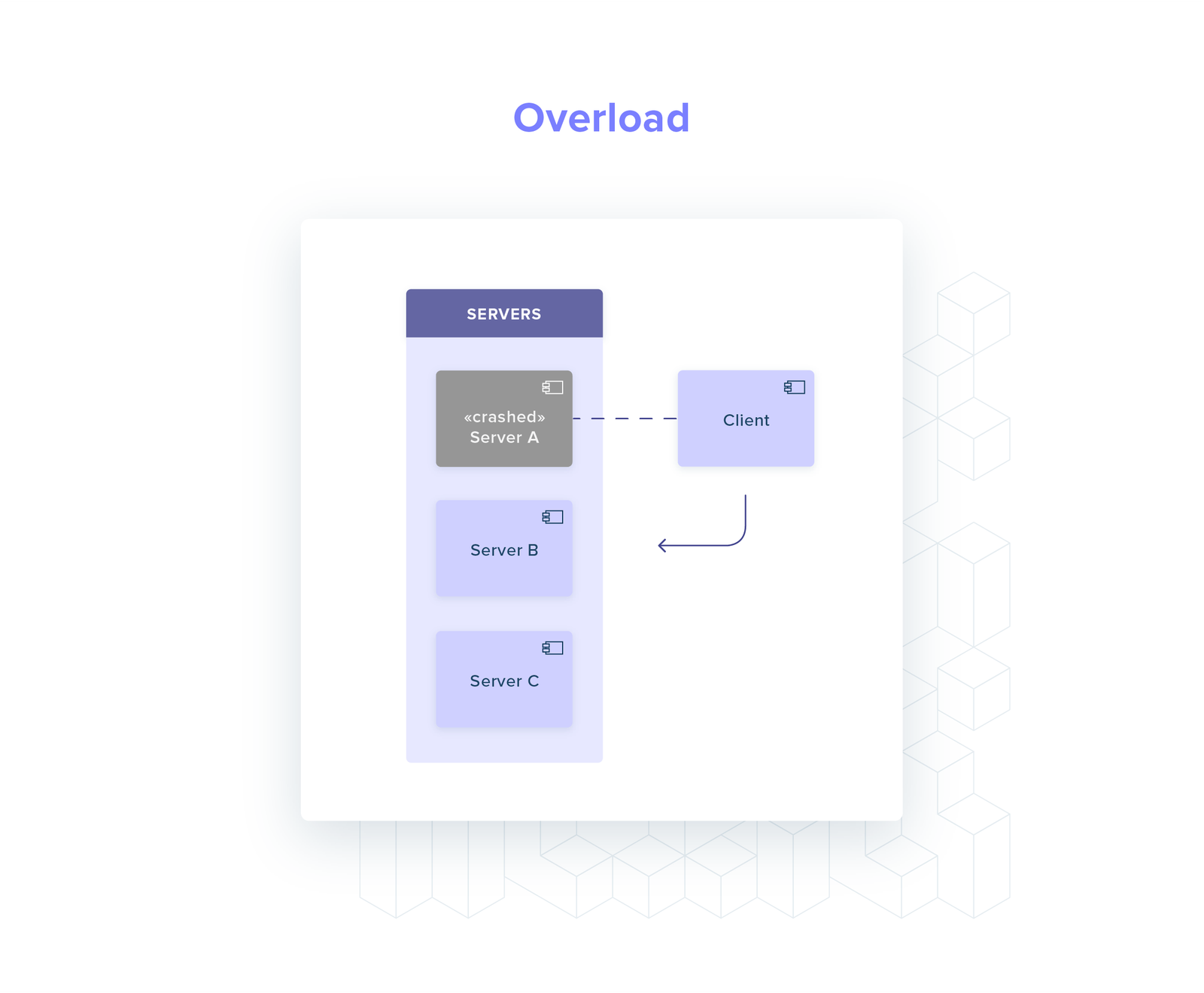
Server C is completely unused, wasting resources and worsening the performance profile of the system (server B is overloaded!).
An overview of gRPC load-balancing approaches
There are a couple of approaches we could take to avoid the scenario we just described:
The servers periodically force the client to reconnect
The client periodically performs service discovery
We introduce an application load balancer
What do all of these options have in common?
Something refreshes the list of available servers – either periodically or on reconnect.
The first two options are fairly straightforward, so let’s dive into the third one to see what types of gRPC application load balancers there are.
For the purpose of this post we will classify gRPC load balancers into two main categories: client side and out of process.
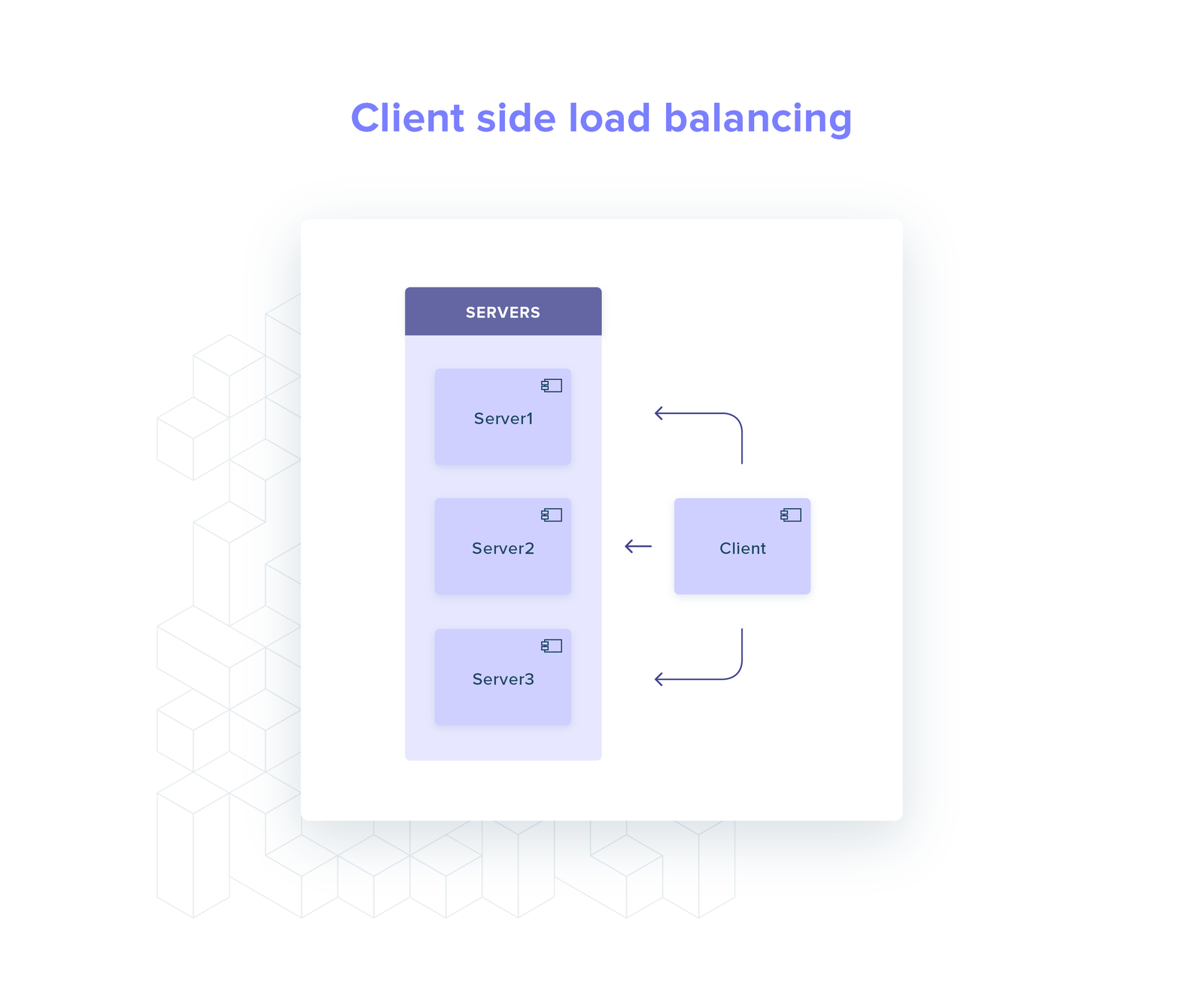
Client side
All the load balancing logic lives in the client: server selection, service discovery, health checks (optional).
Therefore, the client maintains N connections, one for every server, and for every request it chooses a connection to send the request through.
All the logic stays in one place (the client): it is easier to test, and you remove any overhead associated with talking over the network to an out-of-process load balancer.
Conversely, this also adds a lot of complexity and you cannot re-use your implementation across different programming languages.

)
Out of process
In this category the complexity of load balancing is (entirely or partially) moved away from the client into one or more dedicated processes.
These processes can either sit alongside the application (e.g. a sidecar container) or run as standalone services.
Generally speaking, out-of-process gRPC load balancers come in two forms:
Look-aside services that tells the client which server to call
A completely separate service where the load balancing, health checks, load reporting and service discovery is completely transparent to the application (eg Envoy).
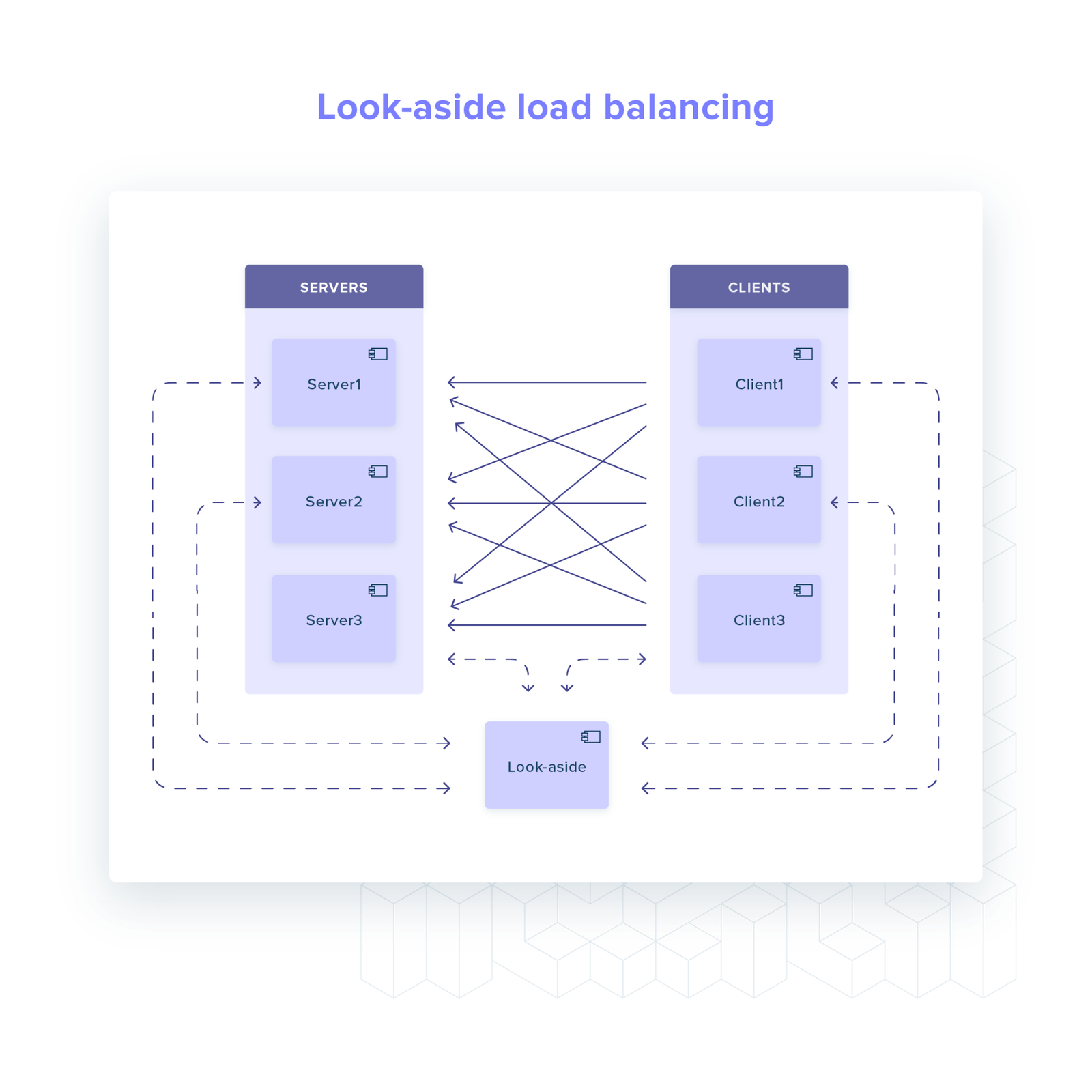
Look-aside
For look-aside load balancers, which we can also classify as a hybrid solution, most of the logic is moved out of client: health checking, service discovery etc.
The client only needs to:
maintain a connection to the look-aside process (what server should I call?)
establish and maintain open connections to all healthy server backends.

)
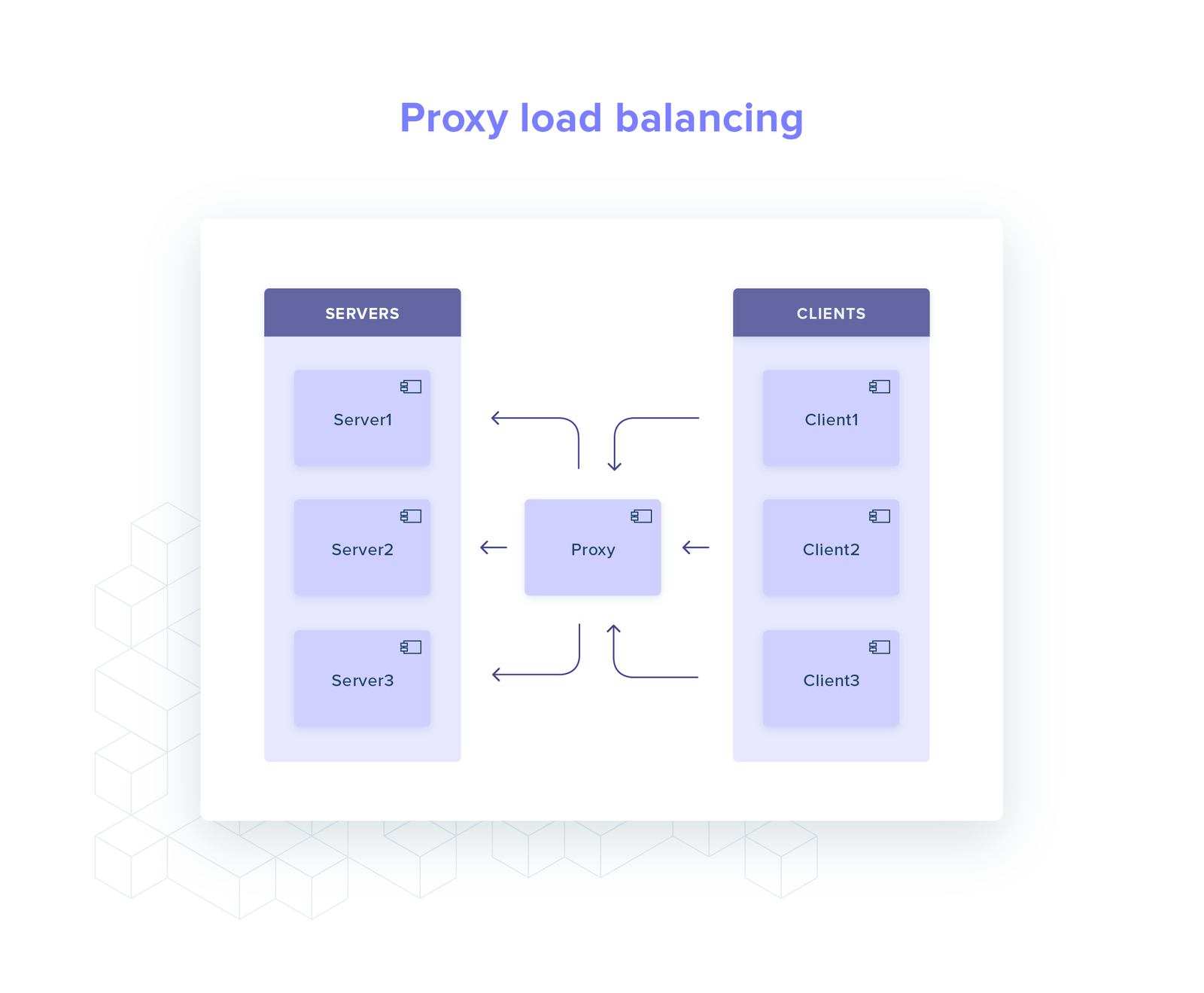
Proxy
With a proxy all the logic is moved away from the client.
This leaves the client very simple as it only needs to maintain a single connection to the the proxy.
There are several ways to incorporate a proxy into your infrastructure:
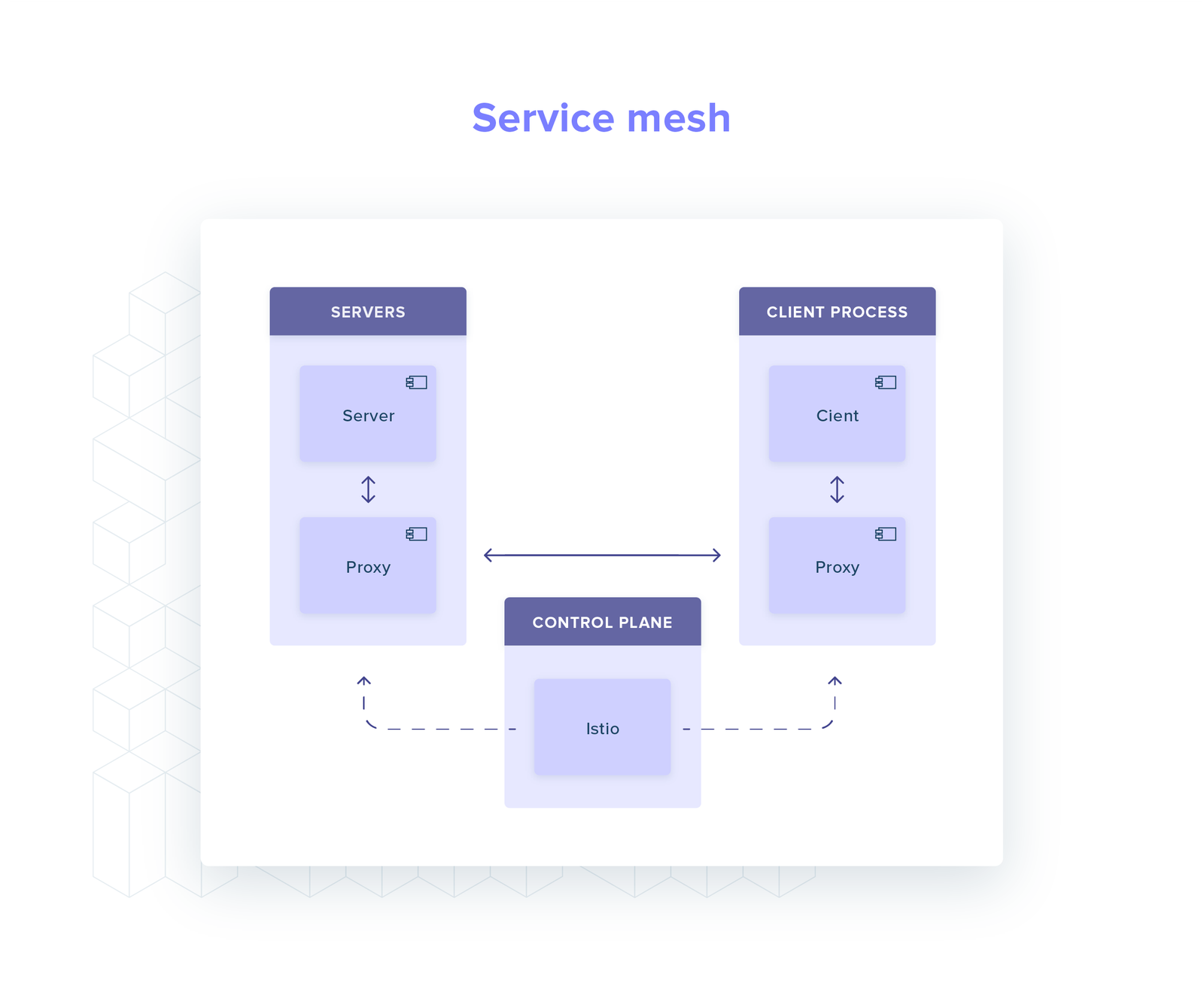
Service mesh: dedicated infrastructure layer that controls service-to-service communication (eg Istio and Linkerd), deployed as a sidecar.
)
Service Proxy: single standalone service that all clients connect to and is configured for each gRPC service.
)
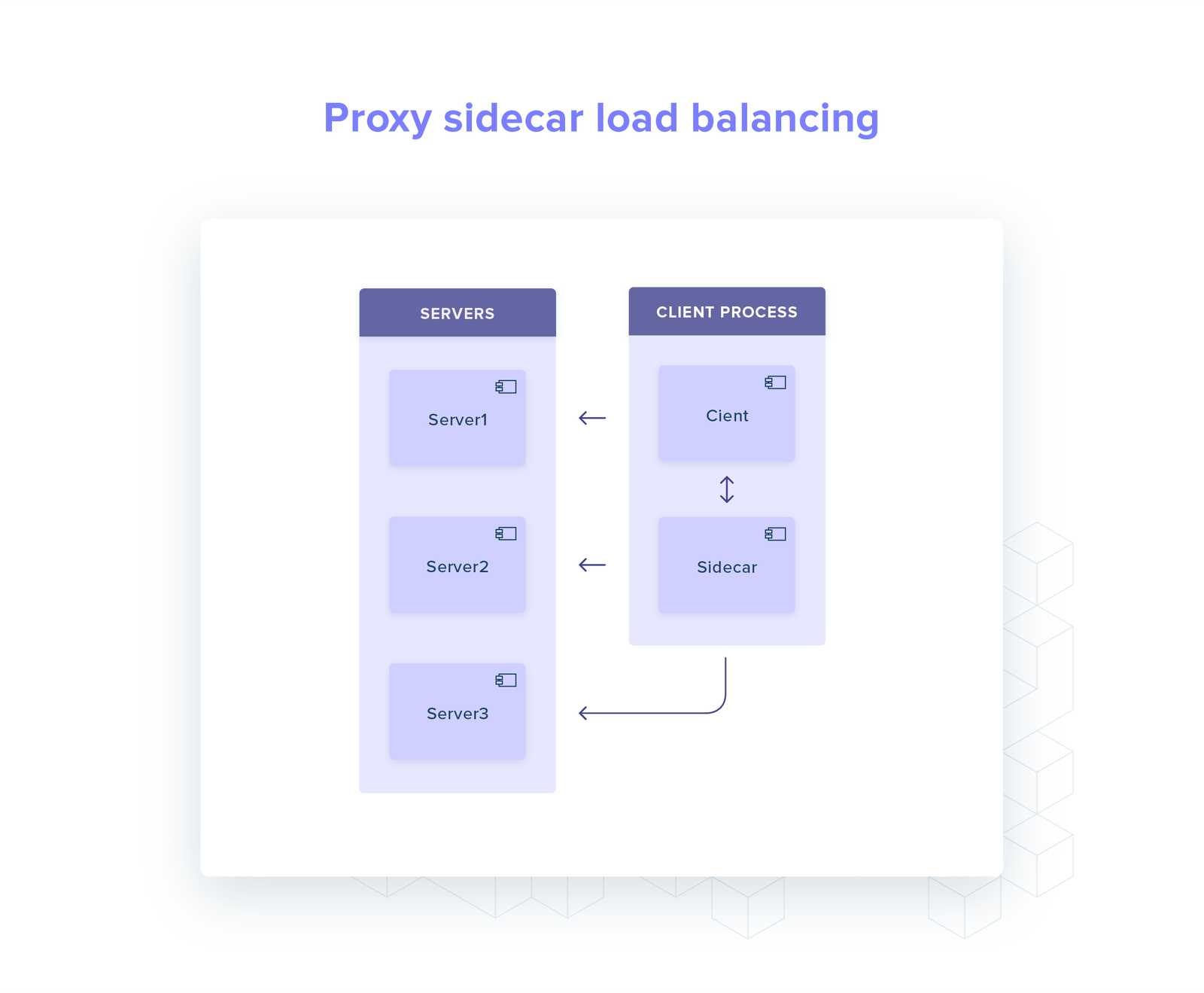
Container sidecar proxy: sidecar proxy is deployed alongside every client that are all configured to proxy across the same gRPC service.
)
However, nothing comes for free – there is always a trade-off:
More moving parts in the hot path, impacting the latency of your system
Both a service mesh and standalone proxies add a lot of complexity to your setup, with novel failure modes. They need to be set up, monitored and maintained.
TrueLayer’s approach
TrueLayer leverages gRPC to have strongly-typed contracts between applications written in various programming languages (C#, Rust, TypeScript, Python).
We currently do not run a service mesh in our Kubernetes clusters, therefore we do not get gRPC load balancing out of the box.
Historical precedent, C#: use an Envoy sidecar
Most of our early gRPC servers and clients were written in C#.
There we used the sidecar approach – a manually-configured Envoy proxy.
With an Envoy sidecar you get a production hardened-solution with a considerable community around it. It was the fastest way to get gRPC load-balancing working at that point in time.
Standalone sidecar proxies, as we discussed, increase the overall complexity of the system: it is another component to configure, operate and understand.
In particular, configuration management scales poorly as the number of services increases while testing and reproducing failure modes locally or on CI is fairly hard.
Rust opportunities
What about Rust? What does the gRPC landscape look like? Is client-side load-balancing viable?
Let’s look at Rust’s most popular gRPC crates:
grpc-rsby TiKV – implements load balancing but no way of updating service IPs;grpc-rust– does not implement load balancing;tonic– implements load balancing and has building blocks for updating endpoints dynamically.
tonic is the closest candidate: everything works out of the box apart from periodic service discovery.
Luckily enough, tonic exposes the API we need to extend its functionality: it offers support for dynamically adding and removing gRPC endpoints on its Channel primitive.
tonic has another upside: it builds on top of tower, a flexible and widely-used middleware framework for networking applications.
In particular, it relies on tower::balance for the load balancing logic. The very same component is used by Linkerd’s data plane proxy: we are building on top of a stack of production-hardened components.
Building a tonic-based solution
We decided to give tonic a shot and invest some time to explore what a feature-complete client-side load balancing channel would look like. The result is ginepro, the crate we open sourced.
This section delves a bit deeper into the implementation details.
The gap we need to fill in tonic is service discovery: we want to periodically refresh the list of healthy server backends – the list of IPs we can send requests to.
We assume that each service name maps to one or more IP addresses (ie replicas of the server).
The logic to resolve the service name is decoupled from the channel implementation via a trait, LookupService:
This contract gives us three properties: we can easily inject failures via a mock implementation to test unhappy scenarios, we do not constrain how IPs are resolved, and we can hide protocol specific nuances like DNS record timeouts.
At TrueLayer, for example, we have two choices when it comes to resolving a service name to a list of IPs: we can either query the Kubernetes’ DNS or query Kubernetes’ API directly (Endpoint resource).
How does LookupService fit into the client logic?
There is an event loop running in the background, managed by our LoadBalancedChannel.
LoadBalancedChannel keeps a set of known endpoints and, on a schedule, triggers service discovery.
We then remove the endpoints that have disappeared and add the newly discovered ones.
It's worth pointing out that the gRPC client does not remove an endpoint if it starts failing: it will keep trying to connect until we explicitly tell the client to remove it (eg the server fails health check probes and gets removed by Kubernetes).
Summary
We were able to test ginepro extensively in CI prior to its deployment – the benefit of client-side solution written in the same stack of the service!
Testing uncovered a few bugs in tonic (around transport and TLS) – we upstreamed patches as a result (1 and 2)
ginepro was deployed in production five months ago, across several gRPC clients.
We haven’t experienced any issue related to gRPC load balancing (yet).
There is a catch: it only works for our Rust services.
It might not be the final chapter of TrueLayer’s own saga for gRPC load balancing.
Does the future hold a service mesh? We shall see.
Nonetheless, there is value in the solution – that’s why we are opening it up to the Rust ecosystem as a whole. We hope other developers can build on top of our work and push forward the state of the gRPC stack within the Rust ecosystem.
ginepro is only the beginning of our open source journey – the next issue will cover the machinery we built to extend reqwest with support for middlewares.
We're hiring! If you're passionate about Rust and building great products, take a look at our job opportunities

)

Why the EU Presidency matters for the future of payments
)
Affordability checks in iGaming: how you run them matters
)
